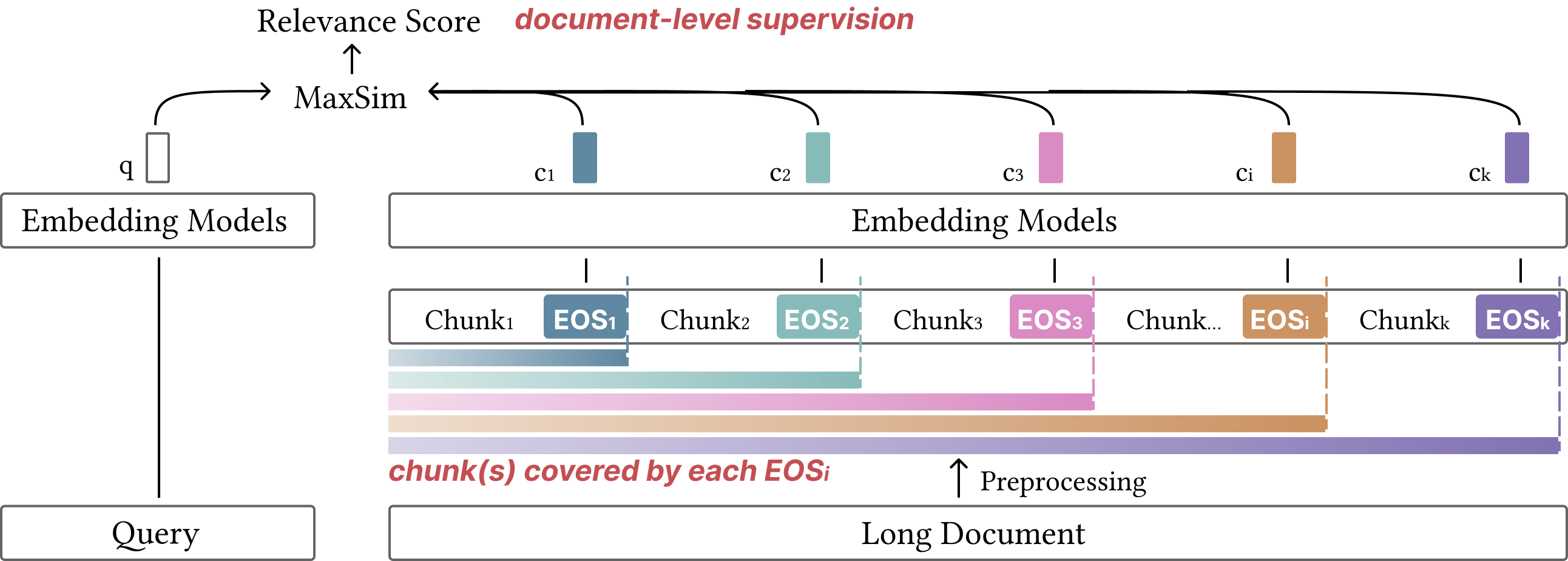
Given a long document with L tokens, MPE partitions it into K consecutive chunks of length s by inserting an EOS token after every s−1 content tokens. The entire sequence is encoded in a single forward pass through a pretrained causal language model. Because attention is left-to-right, the hidden state at each EOS position conditions on all preceding tokens — each prefix embedding captures both its local chunk and all prior context.
MaxSim Scoring
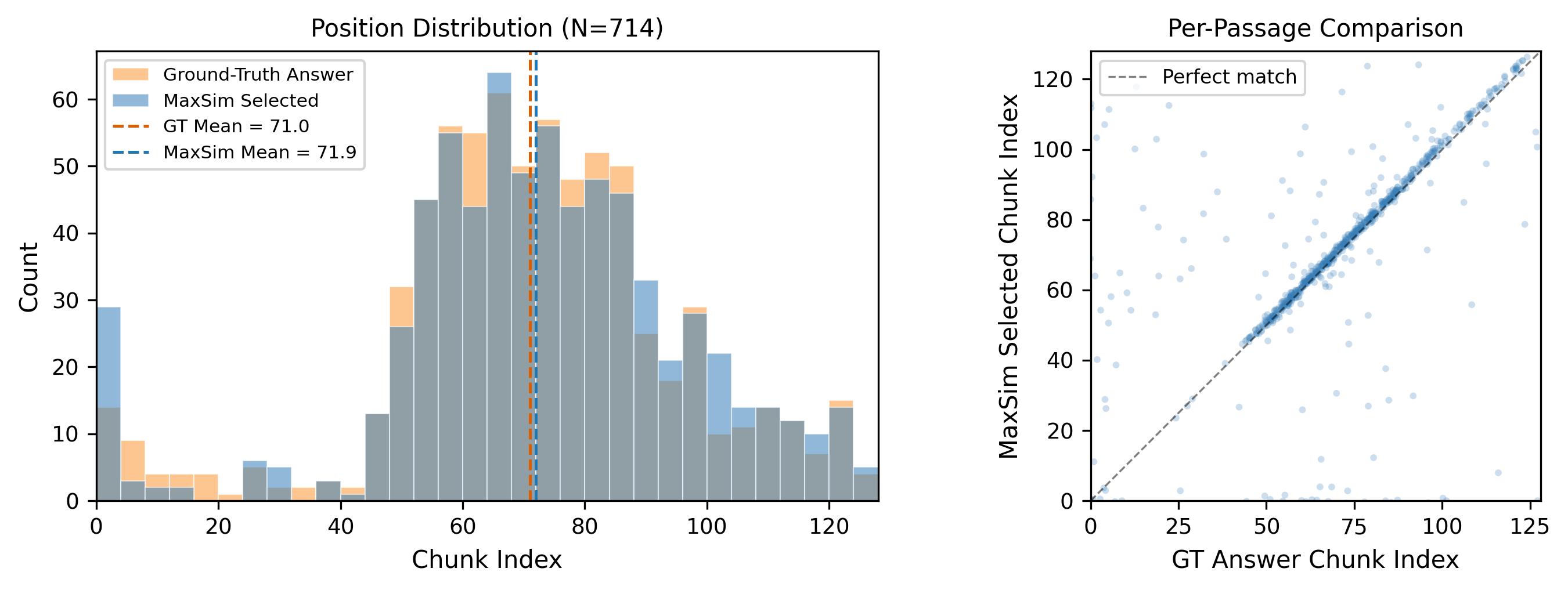
Query–document similarity is defined as the maximum inner product between the query embedding and any prefix embedding. The max operator reflects the localized nature of relevance: a query typically matches a specific region of a document. We train with standard contrastive loss using cross-device negatives. At search time, all prefix embeddings are indexed in a FAISS flat inner-product index.
Random Prefix-Length Augmentation
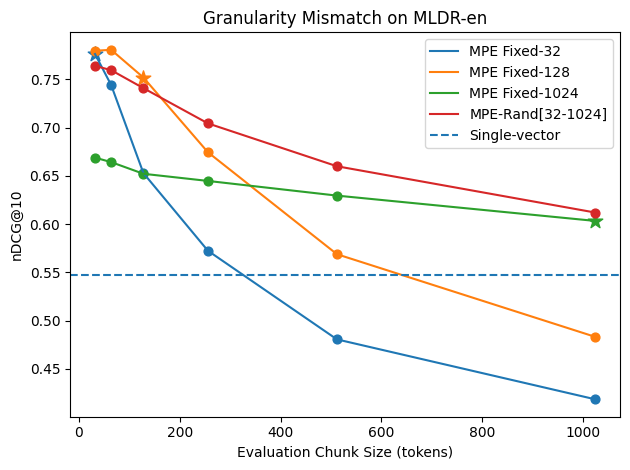
Training with a fixed chunk size can overfit the model to a specific granularity. We introduce random prefix-length augmentation: for each training passage, the chunk size is sampled uniformly from [smin, smax]. This exposes the model to diverse prefix boundaries and enables a single model to generalize across evaluation chunk sizes without retraining.
Configurations
We compare five settings that progressively introduce components:
| Setting |
MaxSim Train |
Cross Chunk-Attn |
Rand-Size |
| Single-vector | × | — | × |
| MaxP | × | × | × |
| MaxP-Train | ✓ | × | × |
| MPE Fixed-N | ✓ | ✓ | × |
| MPE-Rand[a,b] | ✓ | ✓ | ✓ |